이번 글에서는 현재 많은 SOTA model들의 근간이 되고 있는
Transformer 구조를 알아보고자한다.
Transformer는 2017년도에 Google Brain에서 공개한
'Attention is all you need' 에서 소개된 구조이다.
Transformer는 Natural language processing, Computer vision 등
모두에서 다양하게 응용되어 월등한 성능을 보이면서 발전되고 있다.
지금에서야 리뷰하는 것이 너무 뒷북이지만 그만큼 중요하고
개념을 확실히 알아야하기에 정리하는 차원에서 리뷰해보기로 한다.
[Attention Is All You Need 원문 링크]
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Introduce
Transformer는 원래 NLP, 그 중에서도 translation task를 위해서 나오게 되었다.
Translation task에서는 RNN, LSTM model들이 SOTA를 이루어왔으나
RNN, LSTM 기반의 recurrent model들은 기본적으로 time에 따라 sequential하게 연산하여
이전 hidden state($h_{t-1}$)를 다음 hidden state ($h_t$)로 전달하는 과정에서
parallelization이 불가능하였고 longer sequence length에서는 계산량이 너무 많아지며
또 LSTM의 단짝 친구인 long term dependency problem이 존재했기에
이를 해결할 필요성이 존재하였다.
이후 factorization tricks, conditional computation 등으로
recurrent model의 계산 효율을 향상하였으나
근본적으로 sequential computation을 해결하지 못했다는 단점이 존재한다.
이에 따라 Google 연구팀에서는 RNN, LSTM 등을 사용하지 않고 오로지
Attention mechanism만을 활용한 Transformer 구조를 제안하였으며
논문의 제목처럼 'Attention이 바로 너가 찾던 모든 것이다..'하면서 공개되었다.
기존 Seq2Seq의 한계

Transformer가 나오기 전 sequence modeling and transduction model에
주로 사용되던 구조는 Seq2Seq였다.
Seq2Seq model은 translation, summarization과 같이
sequence를 input으로 받아 sequence를 output으로 출력하는
task에 고안된 구조이며 RNN이나 LSTM을 encoder, decoder로 사용해왔다.
(그래서 이름이 Seq2Seq이다.)
Sequence를 input으로 받아들이는 부분을 인코더(encoder),
Sequence를 출력하는 부분을 디코더(decoder)라고 하며
Encoder 부분에서는 입력으로 들어오는 sequence를 일종의 요약된 정보
즉, 문맥 정보를 포함한 고정된 길이의 컨텍스트 벡터(context vector)로 변환하게 된다.
Decoder에서는 encoder에서 생성된 context vector와 <sos> (start of sequence) token을
input으로 받아 <eos> (end of sequence) token이 나올 때까지 수행한다.
보다 자세히 살펴보면 우선 sequence에 있는 단어들을 embedding을 진행한다.
이후 첫 번째 단어의 embedding 값을 input으로 받아
초기화된(ex. zero vector) hidden state를 update한 후
두 번째 단어의 embedding 값을 다시 input으로 받아 hidden state를 또 update를 진행한다.
이렇게 매 time step 즉, 마지막 단어의 embedding 값을 input으로 받게되면
마지막 hidden state 값들이 결국 input sequence에 대한 모든 정보를 담게 된다.
이 hidden state 값들을 이용하여 input sequence에 대한 문맥 정보를 담고 있는
context vector를 생성한 뒤 이를 decoder에 넘겨
decoder의 hidden state를 context vector로 초기화한 후
<sos> token부터 시작하여 매 time step마다
이전에 예측한 단어를 input으로 넘기면서 다음 단어를 예측을 한다.
ex. <sos> -> je -> suis -> ...
여기서 Seq2Seq의 한계점이 존재하게 되는데 이는 다음과 같다.
1. 고정된 size의 context vector로 인하여 정보의 손실이 발생
2. LSTM을 encoder, decoder로 활용할 경우 long term dependency problem 발생
첫 번째로 memory 효율을 높이기 위해 문맥 정보를 context vector로 압축할 경우
통상 고정적인 size로 출력을 하도록 맞춰놓는데,
여기서 longer sequence의 경우 정보의 손실이 발생할 수 있다.
두 번째로 LSTM의 고질적인 문제점인 long term dependency problem이 존재한다.
sequential하게 진행되다보니 초기 token들에 대한 정보가 점점 소실되어
translation task의 경우 output인 번역 결과의 quality가 낮아질 수 밖에 없다.
Attention mechanism
그래서 2015년도에 기존 Seq2Seq의 문제점을 해결하기 위해
Attention mechanism을 Seq2Seq에 적용한 방법론이 공개되었다.
Neural Machine Translation by Jointly Learning to Align and Translate (ICLR, 2015)
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
Attention mechanism의 핵심은 다음과 같다.
고정된 size의 context vector에 input sequence 모든 정보를 담음으로써 발생하는
정보의 손실을 해결하기 위해 마지막 hidden state($h_t$)만을 사용하여 context vector를 생성하지 않고
encoder에서 발생한 모든 hidden state($h_1, h_2, h_3, ..., h_{t-1}$)를 활용하자는 것이다.
보다 구체적으로 Attention mechanism을 정리하면 아래와 같다.
매 time step마다 decoder에서 단어를 예측할 때 encoder의 input sequence를 다시 참고한다.
이 때, input sequence의 구성요소인 모든 단어들을 참고하는 것이 아닌 예측하려는 단어와
가장 관련이 있는 특정 단어를 치중해서 본다.
이렇게 치중(attention)해서 보는 이유로는 Attention mechanism이
decoder가 단어 X를 예측하기 직전의 hidden state는
encoder가 단어 X와 가장 연관이 깊은 단어를 읽은 직후의 hidden state와
상당히 유사할 것이라고 가정하고 있기 때문.
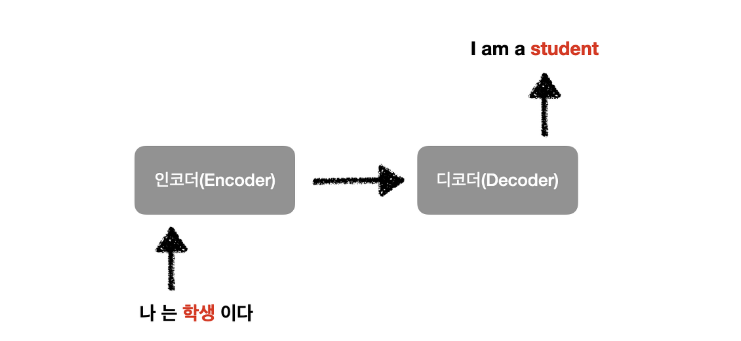
"I am a student."을 프랑스어 문장 "Je suis étudiant."로 번역하는 과정에서
"Je suis" 다음으로 "étudiant"를 예측해야하는 상황이라면
encoder가 "student"를 입력으로 받은 후의 hidden state에 보다 집중하면
더 "étudiant"를 output으로 뽑아낼 확률을 높일 수 있다는 가정을 기반으로 한다.
본 가정에 따라 Attention mechanism의 가정에 따라 가장 관련이 있는 특정 단어를 attention한다면!
현재 decoder의 hidden state와 어떤 encoder의 hidden state와 제일 유사한지 알아야하고,
현재 decoder의 hidden state와 encoder의 모든 hidden state간의 유사도를 계산할 필요성이 존재한다.
Attention mechanism에서는 유사도를 계산하기 위해
현재 time step 시점에서 decoder의 hidden state($h_t$)와
encoder의 모든 hidden state과 dot-product 즉, 내적을 통해서 구한다.

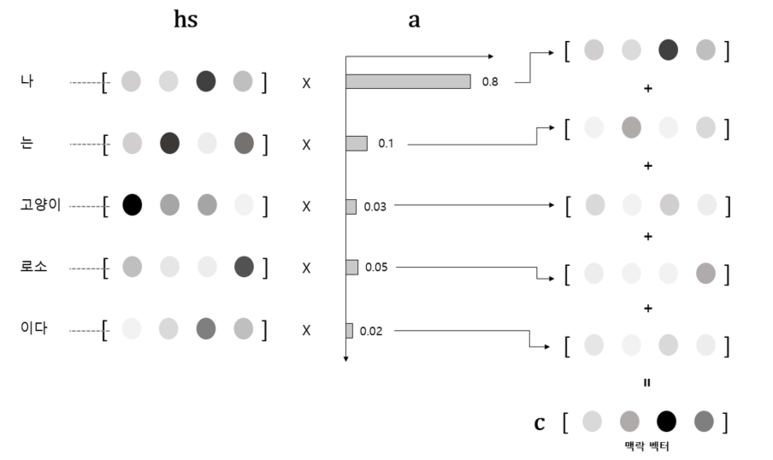
위의 그림처럼 현재 시점이 t=2, 라면 hidden state인 $d_2$와
가장 유사한 encoder hidden state가 무엇인지,
만약 유사하다면 그 정도를 정량화하기위해
dot-product를 수행하면 결과값은 scalar 값이 나오게 된다.
이를 확률로 변환하고자 softmax를 거치면 모든 값들의 합이 1인
확률의 형태로 나오게 되는데 이를 Attention score라고 한다.
어느 정도 유사한지 Attention score로 그 정도를 알았으니 이를 반영하여
모든 encoder의 hidden state들과 dot-product를 진행한 후 sum-up하여 context vector를 생성한다.
즉, 이를 통해 전반적인 문맥 정보를 담고 있음과 동시에
특정 단어에 치중된 context vector를 만들어낸 것이다.
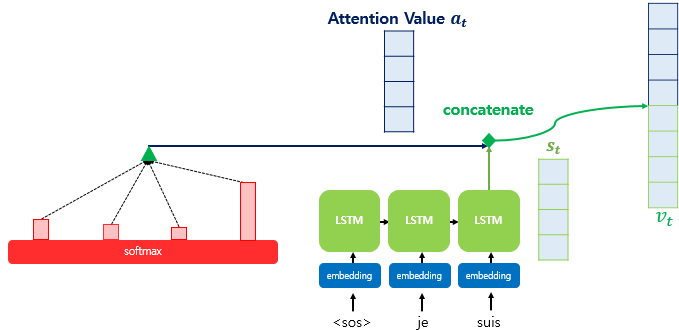
이렇게 만들어낸 context vector(=atten value)를
현재 시점 $t$에서의 hidden state인 $h_t$와
단순히 concatenate해서 이를 input vector로 써서
단어를 예측하는 것이 Attention mechanism이다.
Generalization: Attention (Query, Key, Value)
Attention mechanism을 일반화하면 다음과 같다.
Query: '던져주는 값', 검색어
Key: Query의 값을 기준으로 찾는 대상
Value: Key가 갖고 있는 실제 값
잘 이해가 되지 않으니 위에서 알아본 Seq2Seq with Attention mechanism에 따라 정리해보면 다음과 같다.
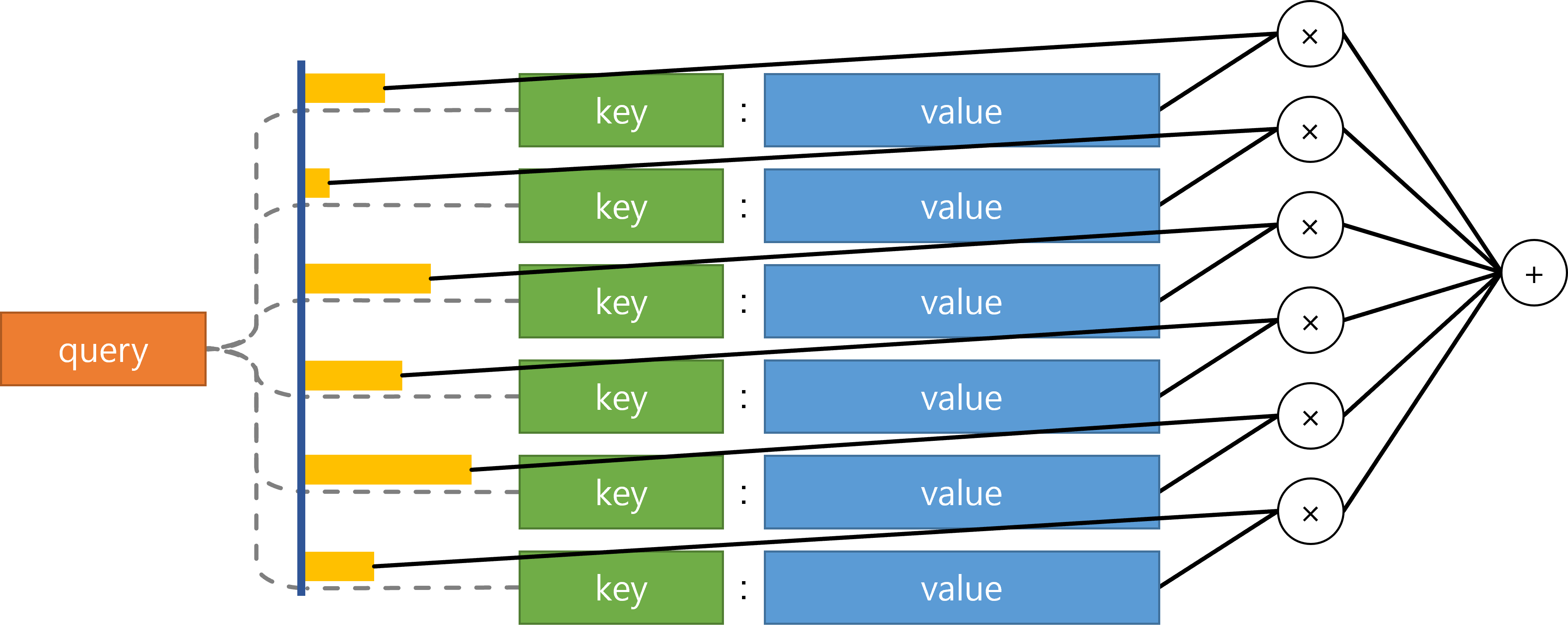
Query: decoder의 hidden state.
즉, 무엇과 가장 유사한지 비교할 때 비교할 현재 t 시점에서의 decoder의 hidden state
Key: encoder의 input token들
Value: Query와 attention score를 곱한 각각의 값들
즉, 비교할 hidden state(=query, 주황색) 와
모든 input token들(=key, 초록색)의 hidden state 값들 간
attention score(=노란색)를 계산한 후 각각 내적하여
스칼라값(=value, 파란색)를 계산한 뒤 이를 다 더해
context vector를 만들어내는 것이 attention 연산이다.
하지만 실제로는 hidden state(=query)와 비교하는 대상은
input token이 아닌 input으로 token이 입력된 뒤의 hidden state이며
value 또한 attention score와 hidden state 값을 내적한 값이라기 보다
python의 dictionary에서 key-value와 동일하게
value 즉, hidden state 값 자체를 의미해서
key와 value가 동일하게 encoder의 hidden state로 사용된다.
조금 헷갈리지만 다시 말하면, decoder의 hidden state(=query)와 비교하기 위해
찾아볼 대상(=key)도 encoder의 hidden state.
key에 해당하는 실제 값(=value)도 encoder의 hidden state이다.
위의 그림은 단순히 개념 이해를 위한 것일뿐 실제 연산 과정에서는
key=value로 encoder의 hidden state들이 사용되니 이를 알고 넘어가자.
Cross-attention vs Self-attention
Transformer에서는 그냥 Attention이 아닌 Self-attention이 계속 등장한다.
Self-attention이 무엇인지 알아보기로 한다.
위에서 Seq2Seq with attention 구조에서는
Query로 decoder의 hidden state,
Key, Value로 encoder의 hidden state를 사용하였다.
이렇게 query ≠ key = value인 구조를 Cross-attention이라 하고
query = key = value인 구조를 Self-attention이라고 한다.
여기서, query, key value가 다르다, 같다라고 하는 것은
값 자체가 동일하다는 의미에서 다르다, 같다가 아닌
출처(encoder인지 decoder인지)가 다르다, 같다를 의미한다.
Self-Attention이 query, key, value가 동일한 출처에서 나온다는 것만 이해하고
왜 도대체 Transformer에서는 Self-Attention을 쓰고 그 효과가 무엇인지는 아래에서 설명하도록 하겠다.
이제 모든 지식은 어렴풋이 정리되었으니 본격적으로 Transformer를 알아보자.
Transformer
Transformer는 앞서 알아본 RNN이나 LSTM을 encoder-decoder로 활용한
Seq2Seq model, Seq2Seq with attention와 다르게
RNN이나 LSTM을 사용하지 않고 오로지 Attention만을 활용한 구조이다.
RNN과 LSTM을 사용하지 않은 이유로는 앞서 설명하였듯이
고정된 size의 context vector로 인한 정보의 손실,
long term dependency problem으로 인한 gradient vanishing/exploding problem 때문이었으며
attention 연산을 통해 모든 encoder의 hidden state를 참조함으로써 long term dependency problem,
정보의 손실 문제를 모두 해결할 수 있고 parallelization 연산이 가능해 학습시간을 줄일 수 있기에
오로지 attention만으로 이루어진 transformer가 등장하게 되었다.
Transformer Architecture
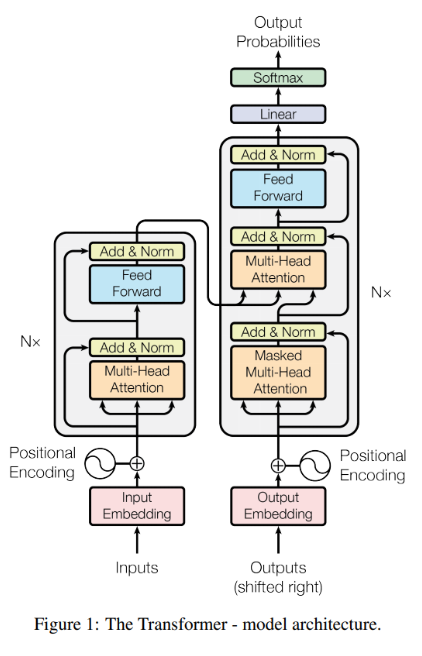
Transformer의 구조는 위와 같다.
정말 복잡하지만 하나씩 차근차근 알아보자.
Transformer 또한 encoder-decoder 부분으로 나뉜다.
왼쪽 회색 박스 영역이 encoder에 해당하고 오른쪽 회색 박스 영역이 decoder에 해당한다.
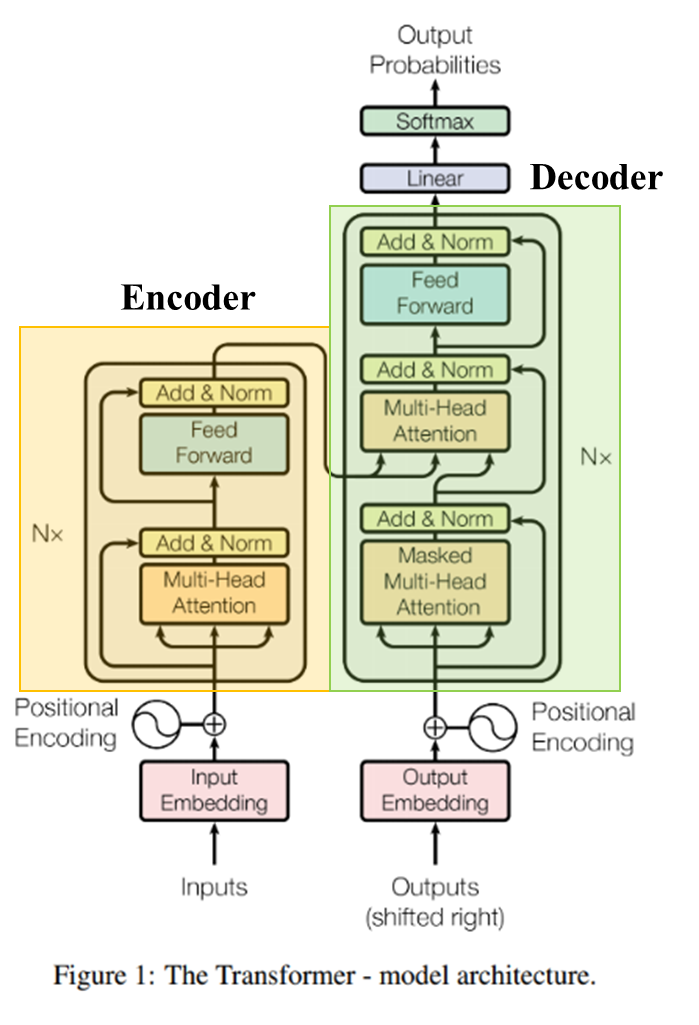
그림에서는 encoder와 decoder가 각각 1개씩 존재하는 것으로 나타났지만
옆에 보면 Nx 가 있는 것으로 보아 실제로는 encoder, decoder가 여러 개 사용되는 것을 알 수 있다.
즉, 노란색 부분의 encoder와 초록색 부분의 decoder를 여러 개 중첩하여 사용한다.
(논문에서는 6개의 encoder, decoder를 사용, N=6)
Scaled Dot-Product Attention
Transformer의 모든 attention 방식에는 attention value를 계산할 때
단순한 Dot-Product가 아닌 Sclaed Dot-Product가 적용되어 attention value가 계산되어진다.
수식은 아래와 같다.
$ Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt{d_k}})V $
이름이 왜 Scaled Dot-Product Attention인 이유로는 바로
일반적인 $QK^{T}$의 내적이 아니라 $\sqrt{d_k}$로 나눠주기 때문인데
굳이 $\sqrt{d_k}$로 나누는 이유는 $Q$(query)와 $K^{T}$(key)의 내적하는 과정에서
query와 key의 길이가 커질수록 내적 값 역시 커지고 이는 softmax의 기울기가 0에 수렴할
가능성이 더욱 높아지기 때문에 0에 도달하지 못하도록 값을 작게 만들게하기 위함이다.
$\sqrt{d_k}$로 나눠줌으로써 기울기가 0으로 수렴하는 gradient vanishing problem을
방지할 수 있기에 Transformer의 모든 attention 연산에서는
Scaled Dot-Product Attention 방식이 적용된다고 한다.
Positional Encoding
아래서부터 차근차근 가보자.
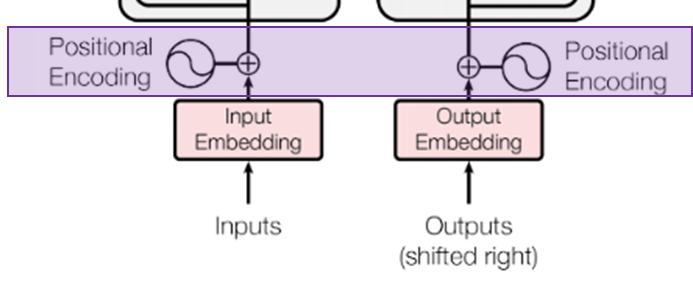
Input sequence가 Embedding 과정을 거친 후
가장 처음 만나는 것은 Positional Encoding 부분이다.
Positional Encoding이 무엇일까?
위에서 Seq2Seq에서는 encoder, decoder로 RNN, LSTM을 활용하였기 때문에
input token들이 순차적으로 입력되는 process였다.
문장에서 단어들의 순서는 매우 중요하기 때문에 순차적으로 처리하는
RNN, LSTM을 활용할 경우 순서 정보를 보존할 수 있지만 transformer 구조에서는
RNN, LSTM을 전혀 활용하지 않고 input token들을 한꺼번에 받게되면 순서 정보를 잃게된다.
단어 순서 정보를 보존하기 위해서 추가된 부분이 바로 Positional Encoding 부분이다.
input token들을 한꺼번에 받아서 처리할 경우 단어 순서 정보를 잃기 때문에
input token들의 순서 정보를 vector로 변환하는 부분이 바로 Positional Encoding 부분이며
논문에서는 Positional Encoding을 위해 sin, cos의 주기함수를 사용한다.
$PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}})$
$PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}})$
짝수일 때는 sin, 홀수일 때는 cos를 사용하는데
sin, cos 중 하나의 주기함수만을 사용하지 않고
두 개의 주기함수를 혼합하여 사용하는 이유는
주기함수 특성 상 한 개의 주기함수를 사용할 경우
다른 위치임에도 불구하고 동일한 값을 가질 수 있기 때문이다.
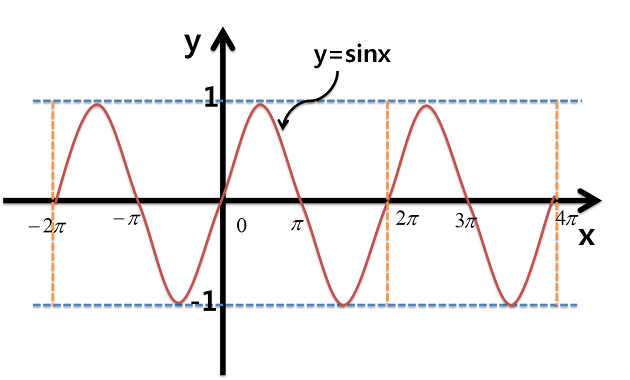
실제로 x가 0일 때와 $\pi$일 때 0으로 동일한 값을 갖는데 한 개의 주기함수만을 사용할 때
두 개의 다른 토큰이 동일한 위치의 값을 의미하는 벡터로 embedding될 수 있기에
짝수일 때와 홀수일 때를 나눠서 sin, cos로 나타내면 이를 방지할 수 있다고 한다.

Transformer에서는 그래서 positional encoding을 짝수일 때와 홀수 일 때를 sin, cos로 나눠서
표현할 경우 위의 그림과 같이 시각화될 수 있는데 개인적으로 잘 이해가 되지 않아
고려대학교 산업경영공학부 DSBA Youtube 중 강필성 교수님의 [08-2: Transformer] 강의 자료
일부분을 가져와 보았다. 개인적으로 위의 그래프보다 훨씬 직관적으로 이해하기 쉬웠다(감사합니다ㅠㅠ).

위의 예시는 embedding dimension을 10으로 두고
token의 개수 또한 10(X1 ~ X10)으로 하였을 때
positional encoding vector가 갖게되는 값들을 시각화한 자료이다.
X1에서 X10으로 갈수록 값이 커지면서 점점 멀어지며
거리를 반영한 위치 정보를 담은 vector값을 갖게되는 것을 확인할 수 있다.
다만 일정하게 증가하지않고 두 번째 행에서 X6보다 X7보다 다소 큰 이유는
주기함수의 특성상 조금씩 값이 튀기 때문이며 이는 큰 영향을 미치지 않는다고 한다.
어찌됐건 거리에 따라 positional encoding이 두 개의 주기함수를 통해 가능하기에
이 방식을 transformer에서 채택하였다.

$i = 0$ 부터 시작하여 짝수일 때는 sin, 홀수일 때는 cos로 하여 위와 같이 변환함으로써
positional encoding이 완료된 vector를 얻을 수 있으며
이 과정에서 이를 input token에 더함으로써 다음 단계로 넘어간다.
여기서 concat을 하지않고 덧셈 연산을 하는 이유는 concat을 할 경우 메모리 낭비가 될 수 있고
dimension이 과도하게 증가할 수도 있기 때문에 덧셈 연산을 한다고 한다.
물론 덧셈 연산을 통해 원래의 input 정보를 훼손하는 반면 concat의 경우 훼손하지 않는다는
장점이 있지만 위의 방식과 같은 positional encoding을 진행할 경우 원래의 정보를 훼손하지 않고
메모리 낭비가 되지않기 때문에 덧셈 연산을 진행한다.
위의 그림에서는 $d_{model}$ 을 4로 설정하였지만 이는 임의로 설정할 수 있는 값이 아니라
덧셈 연산이 가능하도록 input sequence의 길이에 따라 이미 결정된 값이다.
즉, embedding vector의 dimension과 동일해야만 덧셈 연산이 가능해지기 때문에
설정한 embedding dimension에 따라 $d_{model}$이 결정되기에 따로 설정할 필요는 없다.
Multi-Head Attention (Encoder Self-Attention)
Transformer에서는 크게 3가지 종류의 Attention이 존재하는데
이를 구분하는 방법으로는 Attention에 들어오는 화살표의 출처에 따라 나뉜다.

Transformer 안에서 Attention은 크게 아래와 같은 3가지 종류로 나뉜다.
1. Multi-Head Attention (Encoder Self-Attention, 빨간색 부분)
2. Masked Multi-Head (Masked Decoder Self-Attention, 남색 부분)
3. Multi-Head Attention (Encoder-Decoder Attention, 초록색 부분)
1. Multi-Head Attention은 Encoder에서 이루어지는 Self-Attention이고
2. Masked Multi-Head Attention은 Decoder에서 이루어지는 Self-Attention이며
3. Multi-Head Attention은 query는 decoder의 vector이고
key, value는 encdoer의 vector인 Cross-Attention이다.
화살표를 잘보면 1. Multi-Head Attention과 2. Masked Multi-Head Attention은
각각 encoder, decoder에서 positional encoding을 거친 embedding token들이 input으로 입력되어
한 화살표에서 3갈래의 화살표로 나눠지기에 Self-Attention인 것을 알 수 있으며
3. Multi-Head Attention은 두 개의 화살표는 encoder 부분에서 나오고
나머지 한 개의 화살표가 2. Masked Multi-Head Attention에서 나오는 것을 알 수 있다.
즉, 3. Multi-Head Attention에서 encoder에서 나오는 두 개의 화살표가 key, value이며
2. Masked Multi-Head Attention에서 오는 나머지 한 개의 화살표가 query인 것이다.
먼저, Positional Encoding을 지난 encoder의
1. Multi-Head Attention (Encoder Self-Attention) 부분을 먼저 보도록 하자.

Encoder에서 진행되는 1. Multi-Head Attention은
단순히 query, key, value가 동일한 attention이면서
앞에 Multi-Head라는 말만 추가된 것이다.
먼저 'Self-Attention은 query, key, value가 동일하다' 보다 더 정확하게 말하면
'Self-Attention의 query, key, value는 출처가 동일하다'라는 말을 계속 써왔는데
도대체 왜 Transformer는 Self-Attention을 하는지에 대한
설명이 부족한 것 같아 관련 자료를 가져와 보았다.

Self-Attention을 하는 이유는 위의 그림이 잘 설명하고 있다.
우리는 위의 문장처럼 'it'이 가리키는 대상이 'animal'인지 바로 알 수 있으나
기계는 가르쳐 주지 않는 이상 알 수가 없다.
그래서 한 문장안에서 단어들끼리의 연관관계를 알아내기 위해
입력 문장에서 attention을 진행하는 것이 Self-Attention이다.
지들끼리 물어보고 지들끼리 연관관계를 찾는 것이라고 이해하면 편할 것 같다.
그래서 Transformer가 굳이 Self-Attention을 하는 이유는
Self-Attention을 해야만 지시대명사가 포함되어 있는 문장처럼
문맥정보를 정확하게 파악할 수 있기때문에 Self-Attention을 하는 것이라고 정리할 수 있을 것 같다.
그렇다면 Self-Attention 앞에 있는 Multi-Head는 무엇일까?
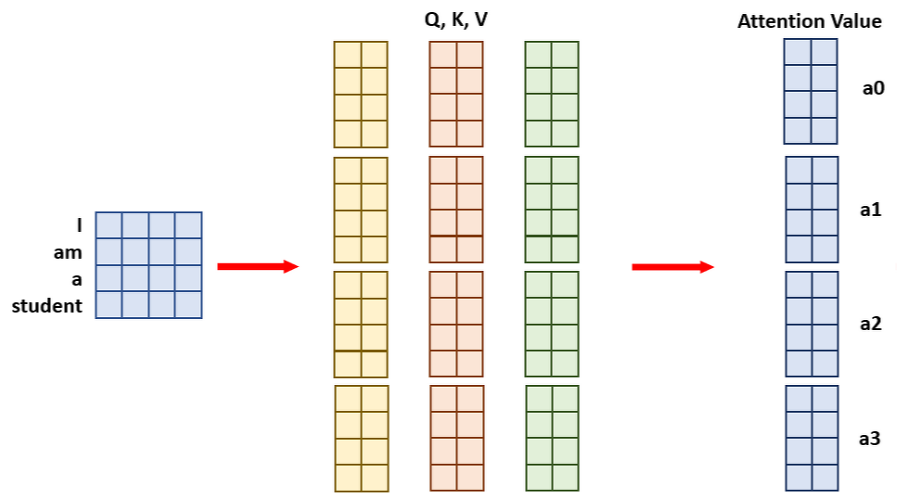
이는 병렬처리를 위해 Head의 수 만큼 query, key, value를 쪼개는 것으로 이해하면 될 것 같다.
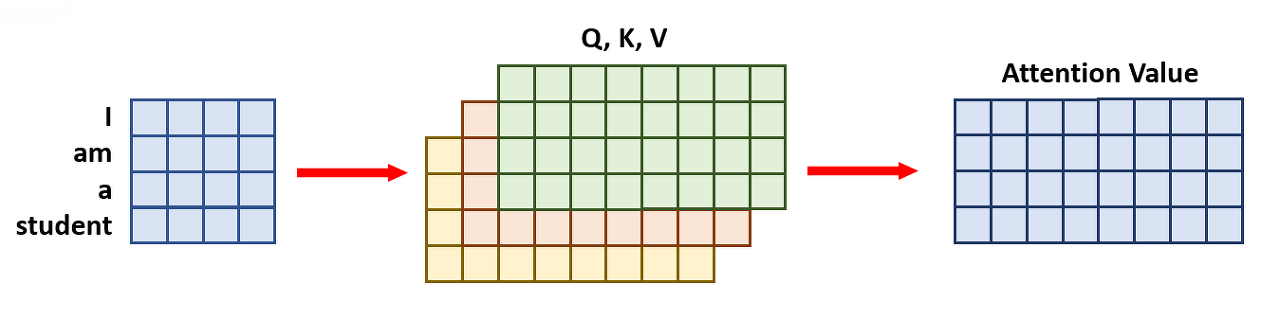
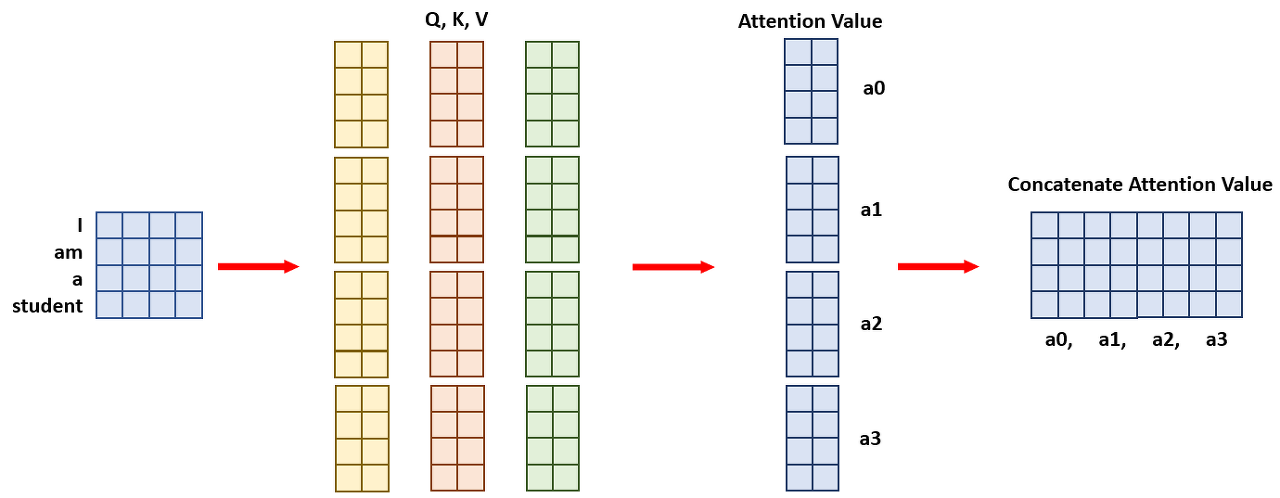
위의 그림이 query, key, value로 [4X8] 행렬로 Attention value를 계산하는 과정이라면
Multi-Head attention에서는 num_head의 수를 4로 둔다면 4등분한 [4X2] 행렬을 각각
query, key, value로 두어 이를 마지막에 concat하는 과정인 것이다.
마지막에 concat하면 결과값은 [4X8]로 Single self-attention과
Multi-Head attention이 동일한데 굳이 병렬적으로 쪼개는 이유는 무엇일까?
이는 크게 2가지의 장점을 얻을 수 있다고 한다.
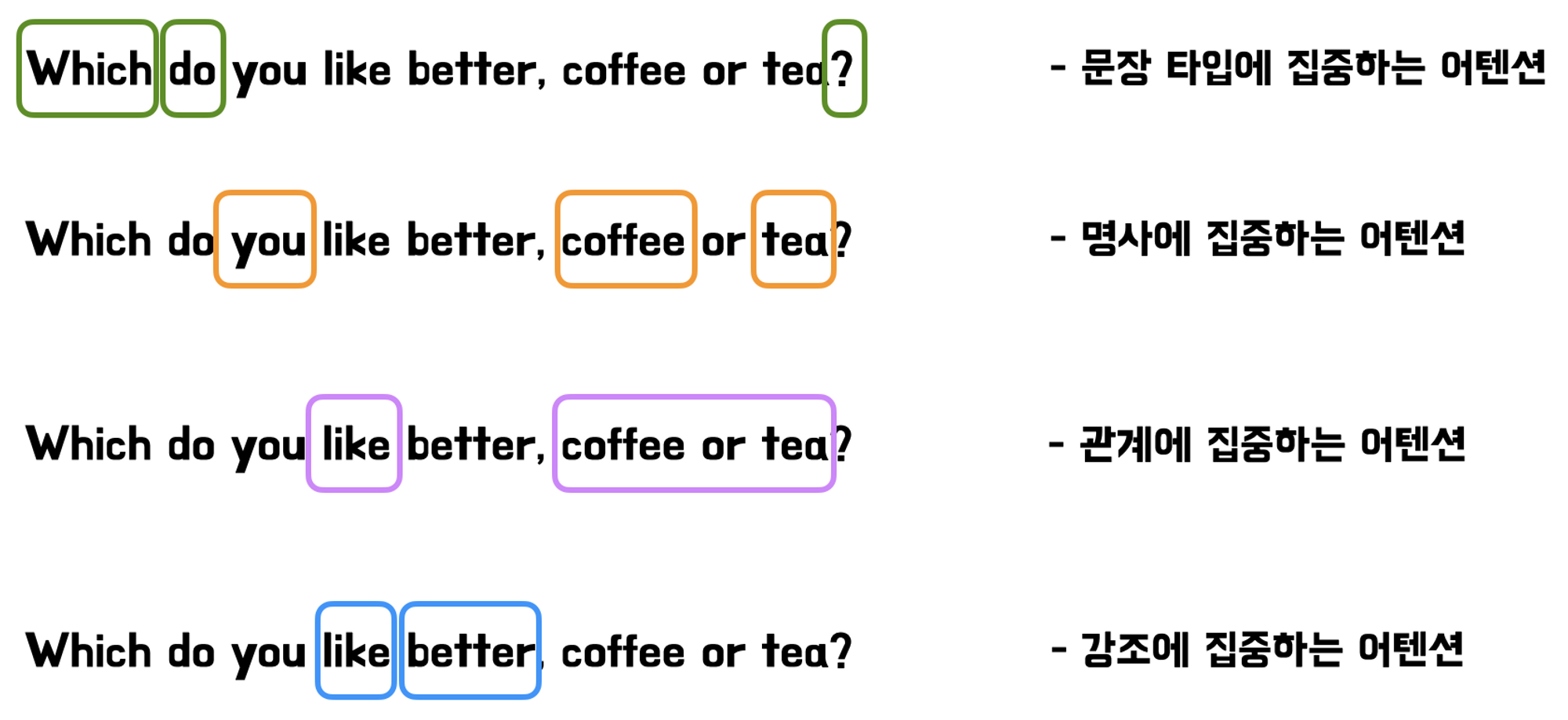
첫 번째로는 입력 토큰간의 더욱 복잡한 관계를 다룰 수 있다는 장점이 존재한다.
head의 수를 여러 개 가짐으로써 위의 그림처럼 각각 문장 타입, 명사 등 다양한 관점에서
attention하기 때문에 다양한 정보를 얻어 input sequence를 표현할 수 있다고 한다.
두 번째로는 GPU의 병렬 처리 연산을 통해 연산 속도를 높이고자 하기 위함이다.
한 번에 [4X8] 단위의 연산을 진행하는 것보다 [4X2]를 4번 진행하는 병렬 연산이
훨씬 연산이 효율적이기 때문에 속도가 매우 빨라진다고 한다.
그래서 정리해보면 Multi-Head Attention은 input sequence안에서 attention을 진행하되
여러 개의 head를 통해 병렬적으로 attention을 진행하는 것으로 정리할 수 있다.
Add & Norm
다음으로 만나게되는 Add & Norm을 보기로 한다.

Multi-Head Attention을 거친 후 다음으로는 Add & Norm을 만나게 된다.
이는 Residual connection (Add)과 Layer Normalization (Norm)을 의미한다.
Residual connection은 Resnet(2015, CVPR)에서 처음 등장한 residual learning과 동일한 개념이며
residual learning은 저번 포스팅 글에서 다루었기에 보고오시길 추천드린다.
https://woongchan789.tistory.com/9
[Paper review] Resnet - Deep Residual Learning for Image Recognition (2015, CVPR)
너무 늦은 리뷰이지만 공개 당시에 획기적인 방법과 높은 성능으로 인해 아직까지도 backbone으로 많이 응용되고 있는 Resnet 논문을 리뷰해보고자 한다. [Deep Residual Learning for Image Recognition 원문 링
woongchan789.tistory.com
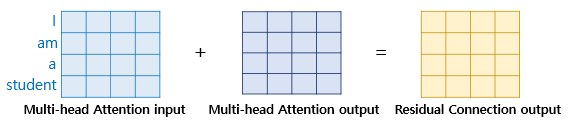
Residual learning은 간단하게 말하면 원본 input x의 값을
몇 개의 layer 이후에 추가하여
더욱 빠르게 optimization이 되게하며
동시에 gradient vanishing problem을 해결할 수 있는 방법이다.
이는 input의 dimension과 multi-head attention 이후의 출력값의
dimension이 동일하기 때문에 덧셈 연산이 가능한 것이며
이로써 모델이 학습하는 과정에서 더욱 optimization이 빠르도록 만들어준다.
수식으로 정리하면 다음과 같다.
$ H(x) = x + Multi-Head Attention(x) $
다음으로 Layer Normalization에 대해 알아보자.
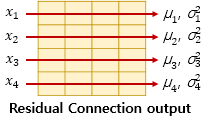
Layer normalization은 정규화 과정과 동일하다.
input으로는 residual connection 이후의 벡터값을 대상으로 정규화를 진행한다.
$LN = LayerNorm(x + Sublayer(x))$
수식은 아래와 같다.
$\hat{x}_{i, k} = \frac{x_{i, k}-μ_{i}}{\sqrt{σ^{2}_{i}+\epsilon}}$
$ϵ$는 분모가 0이 되는 것을 방지하기 위함이며
실제로 학습과정에서는 $γ$와 $β$라는 vector로 두어 학습가능한 parameter로 학습을 진행한다.
$ln_{i} = γ\hat{x}_{i}+β = LayerNorm(x_{i})$
참고로 $γ$와 $β$는 초기값으로 1과 0인 vector로 둔다.

Add & Norm은 encoder 뿐만 아니라 decoder 내부에서도 반복해서 등장하는데
모두 동일하게 residual connection과 layer normalization을 진행하는 것이다.
Feed Forward
다음은 Feed Forward이다.
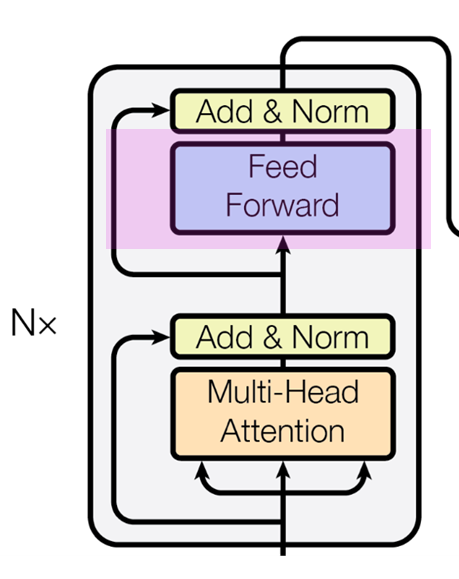
이 부분은 Multi-Head attention을 통해 나온 결과들을 모두 합치는 과정이라 이해하면 될 듯하다.
위의 그림의 경우 Multi-head attention을 통해 attention value가 계산이 되고
이를 Add & Norm에 통과시키게 되면 각각의 4개의 sub layer로 존재하게되는데
이 4개의 각각의 값들을 FFN(Feed Forward Network)에 통과시켜 합치는 과정이 Feed Forward이다.
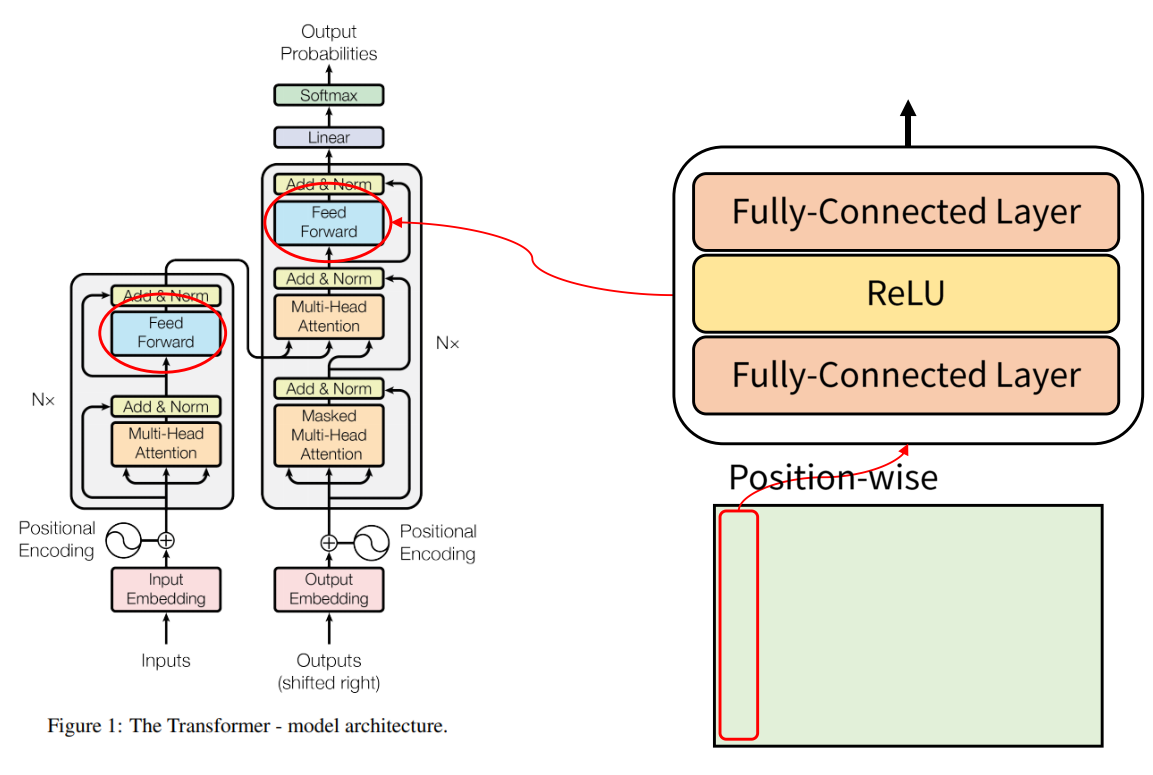
본 논문에서는 FFN으로 layer의 수는 2, activation funcion으로는 ReLU를 사용하였으며
이를 통해 input vector를 고차원 공간으로 mapping하고 non-linear하게
모델의 표현력을 향상시킨다.
Masked Multi-Head Attention (Masked Decoder Self-Attention)

다음으로 이제 Decoder 부분을 보도록 한다.
동일하게 output sequence에 대해 embedding한 후 positional encoding을 거쳐
Self-Attention을 하는 과정이 Masked Multi-Head Attention이다.
다만, 앞에 Masked라는 부분이 추가된 것이 특징인데
이는 Transformer 내에서 attention value를 계산할 때 모든 input sequence를 입력으로 받아
병렬처리하는 과정에서 encoder는 입력 문장이기 때문에 상관이 없지만
출력부분의 decoder 부분에서는 과거시점($t$)에서 미래시점($t+1$)의 정보를 참고할 수 있기 때문에
이를 방지하고자 미래 시점의 정보를 masking하여 self-attention을 하는 과정이 바로
Masked Multi-Head Attention이다.
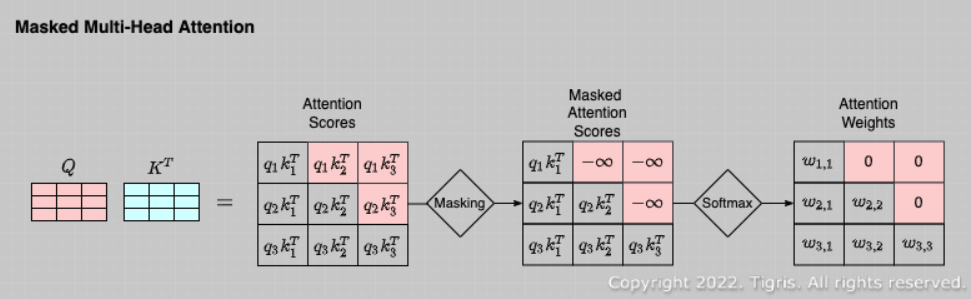
위와 같이 [3X3] 행렬의 attention score이 있다고 하자.
Attention score의 $(i, j)$ 번째가 의미하는 것이
$i$번째의 query와 $j$번째의 key, value 간의 유사도라고 할 경우
미래 시점의 정보를 참고하지 않기 위해 $i < j$ 인 값들을 전부 참고하지 않아야한다.
Masked Multi-Head Attention에서는 $i < j$ 인 값들을 전부 참고하지않기 위해
$i < j$ 인 값들을 전부 $-\infty$로 변환한 후 softmax를 취해
attention weight를 모두 0으로 만들어 버린다.
이로써 현재 시점에서 미래 시점의 정보들을 참고하지 않은 채로
self-attention을 진행할 수 있다.
Multi-Head Attention (Encoder-Decoder Attention)
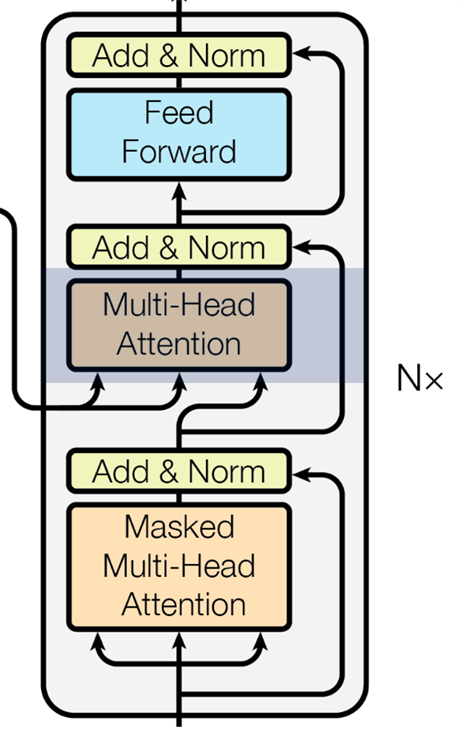
마지막으로 Masked Multi-Head Attention 후 Add & Norm을 거쳐 만나게되는
Multi-Head Attention (Encoder-Decoder Attention)을 알아보도록 하자.
Multi-Head Attention에 input으로 들어오는 3개의 화살표가
2개의 출처는 encoder로부터 오고
나머지 한개가 Masked Multi-Head Attention -> Add & Norm 후로부터 온다.
이는 위에서 알아보았던 Attention mechanism의 과정이며
보다 더 정확히 말하면 query는 decoder의 hidden state이고
key, value는 encoder의 hidden state인 cross-attention을 수행하는 단계이다.
입력 문장 안에서 self-attention을 수행하여 입력 문장의 문맥 정보를 파악했으니
이제는 decoder의 각 hidden state마다 encoder의 hidden state들 중 가장 유사한
hidden state를 찾아 그에 따라 attention하는 과정인 것이다.
Linear & Softmax

위의 Multi-Head Attention을 거친 후 non-linear하게 합치는 FFN을 거쳐
이제 최종적으로 단어를 예측할 준비가 모두 완료가 되었다.
논문에서는 이러한 encoder, decoder block을 6개를 중첩하여 쌓았으며
마지막 6번째 decoder의 출력값을 vocab_size만큼 linear하게 펼친 뒤
softmax를 통과시켜 단어를 최종적으로 예측한다.
끝으로
Transformer를 정리하다보니 머릿속으로 정리는 되었으나
말로 표현하는데 어려워 중구난방으로 작성한 것 같다.
잘못된 부분이 있다면 댓글로 알려주시면 감사하겠습니다..
쓰다보니 이렇게 길어질 줄 몰랐으나
이렇게 정리하고보니 또 그런 생각이 든다.
이런 걸 어떻게 생각해냈을까..
앞으로 논문리뷰할 때마다 꼬리글로 '이런 걸 어떻게 생각해냈을까..'는
무조건 달릴 것 같다. 그냥 유행어로 만들어야겠다. 이어생..
'Study > 논문리뷰' 카테고리의 다른 글
| [Paper review] VAE - Auto-Encoding Variational Bayes (2013, ICLR) (0) | 2023.05.31 |
|---|---|
| [Paper review] Resnet - Deep Residual Learning for Image Recognition (2015, CVPR) (2) | 2023.04.24 |